Arbejde med XML i Groovy
1. Introduktion
Groovy leverer et betydeligt antal metoder dedikeret til at krydse og manipulere XML-indhold.
I denne vejledning demonstrerer vi, hvordan du gør det tilføje, redigere eller slette elementer fra XML i Groovy ved hjælp af forskellige tilgange. Vi viser også, hvordan man gør det oprette en XML-struktur fra bunden.
2. Definition af modellen
Lad os definere en XML-struktur i vores ressourcemappe, som vi bruger i vores eksempler:
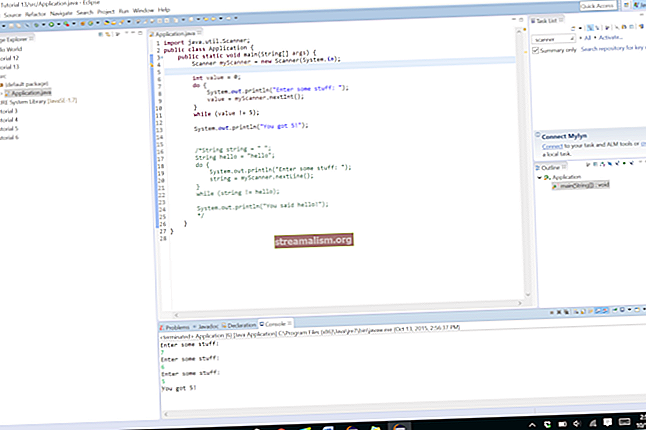
Første trin i Java Siena Kerr 2018-12-01 Dockerize din SpringBoot-applikation Jonas Lugo 2018-12-01 SpringBoot tutorial Daniele Ferguson 2018-06-12 Java 12 indsigt Siena Kerr 2018-07-22 Og læs det ind i en InputStream variabel:
def xmlFile = getClass (). getResourceAsStream ("articles.xml")3. XmlParser
Lad os begynde at udforske denne strøm med XmlParser klasse.
3.1. Læsning
Læsning og parsing af en XML-fil er sandsynligvis den mest almindelige XML-handling, som en udvikler skal udføre. Det XmlParser giver en meget ligefrem grænseflade beregnet til netop det:
def artikler = ny XmlParser (). parse (xmlFile)På dette tidspunkt kan vi få adgang til attributter og værdier for XML-struktur ved hjælp af GPath-udtryk.
Lad os nu implementere en simpel test ved hjælp af Spock for at kontrollere, om vores artikler objektet er korrekt:
def "Skal læse XML-fil ordentligt" () {givet: "XML-fil" når: "Brug af XmlParser til at læse filen" def articles = new XmlParser (). parse (xmlFile) then: "Xml is downloaded korrekt" articles. '* '.størrelse () == 4 artikler.artikel [0] .author.firstname.text () == "Siena" artikler. artikel [2].' release-date'.text () == "2018-06- 12 "articles.article [3] .title.text () ==" Java 12 insights "articles.article.find {it.author. '@ Id'.text () ==" 3 "}. Author.firstname. tekst () == "Daniele"}For at forstå hvordan man får adgang til XML-værdier og hvordan man bruger GPath-udtryk, lad os fokusere et øjeblik på den interne struktur af resultatet af XmlParser # parse operation.
Det artikler objekt er en forekomst af groovy.util.Node. Hver Node består af et navn, attributkort, værdi og overordnet (som kan være enten nul eller en anden Knude).
I vores tilfælde er værdien af artikler er en groovy.util.NodeList eksempel, som er en indpakningsklasse til en samling af Nodes. Det NodeListe udvider java.util.ArrayList klasse, som giver ekstraktion af elementer efter indeks. For at opnå en strengværdi på en Knude, vi bruger groovy.util.Node # tekst ().
I ovenstående eksempel introducerede vi et par GPath-udtryk:
- articles.article [0] .author.firstname - få forfatterens fornavn til den første artikel - artikler.artikel [n] direkte adgang til nartikel
- ‘*' - få en liste over artikel'S børn - det svarer til groovy.util.Node # børn ()
- forfatter.'@id ' - Hent forfatter elementets id attribut - forfatter.'@attributnavn ' får adgang til attributværdien efter dens navn (ækvivalenterne er: forfatter [‘@ id '] og [e-mail beskyttet])
3.2. Tilføjelse af en node
Svarende til det foregående eksempel, lad os først læse XML-indholdet i en variabel. Dette giver os mulighed for at definere en ny node og føje den til vores artikelliste ved hjælp af groovy.util.Node # tilføj.
Lad os nu implementere en test, der beviser vores pointe:
def "Skal tilføje node til eksisterende xml ved hjælp af NodeBuilder" () {givet: "XML-objekt" def artikler = ny XmlParser (). parse (xmlFile) når: "Tilføjelse af node til xml" def artikelNode = ny NodeBuilder (). artikel ( id: '5') {title ('Traversing XML in the nutshell') forfatter {firstname ('Martin') efternavn ('Schmidt')} 'release-date' ('2019-05-18')} articles.append (articleNode) derefter: "Node tilføjes til xml korrekt" artikler. '*'. størrelse () == 5 artikler.artikel [4] .title.text () == "Traversering af XML i nøddeskal"}Som vi kan se i ovenstående eksempel, er processen ret ligetil.
Lad os også bemærke, at vi brugte groovy.util.NodeBuilder, som er et pænt alternativ til at bruge Node konstruktør til vores Node definition.
3.3. Ændring af en node
Vi kan også ændre værdierne for noder ved hjælp af XmlParser. Lad os igen analysere indholdet af XML-filen. Dernæst kan vi redigere indholdsknudepunktet ved at ændre værdi felt i Node objekt.
Lad os huske det mens XmlParser bruger GPath-udtryk, henter vi altid forekomsten af NodeListe, så for at ændre det første (og eneste) element skal vi få adgang til det ved hjælp af dets indeks.
Lad os kontrollere vores antagelser ved at skrive en hurtig test:
def "Skal ændre node" () {givet: "XML-objekt" def articles = ny XmlParser (). parse (xmlFile) når: "Ændring af en af nodernes værdi" articles.article.each {it.'release-date '[0] .value = "18.05.2019"} derefter: "XML opdateres" articles.article.findAll {it.'release-date'.text ()! = "18.05.2019"}. er tom() }I ovenstående eksempel har vi også brugt Groovy Collections API til at krydse NodeListe.
3.4. Udskiftning af en node
Lad os derefter se, hvordan man udskifter hele noden i stedet for bare at ændre en af dens værdier.
På samme måde som at tilføje et nyt element, bruger vi NodeBuilder til Node definition og derefter erstatte en af de eksisterende knudepunkter i den ved hjælp af groovy.util.Node # erstatteNode:
def "Skal erstatte node" () {givet: "XML-objekt" def articles = ny XmlParser (). parse (xmlFile) når: "Tilføjelse af node til xml" def articleNode = ny NodeBuilder (). artikel (id: '5' ) {title ('Traversing XML in the nutshell') forfatter {firstname ('Martin') efternavn ('Schmidt')} 'release-date' ('2019-05-18')} articles.article [0] .replaceNode (articleNode) derefter: "Node tilføjes ordentligt til xml" artikler. '*'. størrelse () == 4 articles.article [0] .title.text () == "Traversing XML in the nutshell"}3.5. Sletning af en node
Sletning af en node ved hjælp af XmlParser er ret vanskelig. Selvom Node klasse giver fjerne (Node barn) metode, i de fleste tilfælde ville vi ikke bruge den i sig selv.
I stedet viser vi, hvordan du sletter en node, hvis værdi opfylder en given betingelse.
Som standard adgang til de indlejrede elementer ved hjælp af en kæde af Node.NodeList referencer returnerer en kopi af de tilsvarende børneknuder. På grund af det kan vi ikke bruge java.util.NodeList # removeAll metode direkte på vores artikel kollektion.
For at slette en node ved et predikat skal vi først finde alle noder, der matcher vores tilstand, og derefter gentage dem og påberåbe sig java.util.Node # fjern metode på forældrene hver gang.
Lad os implementere en test, der fjerner alle artikler, hvis forfatter har et andet id end 3:
def "Skal fjerne artiklen fra xml" () {givet: "XML-objekt" def articles = new XmlParser (). parse (xmlFile) når: "Fjernelse af alle artikler undtagen dem med id == 3" articles.article .findAll { it.author. '@ id'.text ()! = "3"}. hver {articles.remove (it)} derefter: "Der er kun én artikel tilbage" articles.children (). størrelse () == 1 articles.article [0] .author. '@ id'.text () == "3"}Som vi kan se, som et resultat af vores fjernelse, modtog vi en XML-struktur med kun en artikel, og dens id er 3.
4. XmlSlurper
Groovy tilbyder også en anden klasse dedikeret til at arbejde med XML. I dette afsnit viser vi, hvordan man læser og manipulerer XML-strukturen ved hjælp af XmlSlurper.
4.1. Læsning
Som i vores tidligere eksempler, lad os starte med at analysere XML-strukturen fra en fil:
def "Skal læse XML-fil korrekt" () {givet: "XML-fil" når: "Brug af XmlSlurper til at læse filen" def articles = new XmlSlurper (). parse (xmlFile) derefter: "Xml er korrekt indlæst" artikler. '* '.størrelse () == 4 artikler.artikel [0] .forfatter.firnavn == "Siena" artikler. artikel [2].' frigivelsesdato '== "2018-06-12" artikler. artikel [3] .title == "Java 12 indsigt" articles.article.find {it.author.'@id '== "3"} .author.firstname == "Daniele"}Som vi kan se, er grænsefladen identisk med den for XmlParser. Imidlertid bruger outputstrukturen groovy.util.slurpersupport.GPathResult, som er en indpakningsklasse til Node. GPathResult giver forenklede definitioner af metoder såsom: lige med() og toString () ved indpakning Node nr. Tekst (). Som et resultat kan vi læse felter og parametre direkte ved kun at bruge deres navne.
4.2. Tilføjelse af en node
Tilføjelse af en Node ligner også meget brug XmlParser. I dette tilfælde groovy.util.slurpersupport.GPathResult # appendNode giver en metode, der tager en forekomst af java.lang.Objekt som et argument. Som et resultat kan vi forenkle nye Node definitioner efter samme konvention indført af NodeBygger:
def "Skal tilføje node til eksisterende xml" () {givet: "XML-objekt" def articles = new XmlSlurper (). parse (xmlFile) når: "Tilføjelse af node til xml" articles.appendNode {artikel (id: '5') {title ('Traversing XML in the nutshell') forfatter {firstname ('Martin') efternavn ('Schmidt')} 'release-date' ('2019-05-18')}} artikler = ny XmlSlurper (). parseText (XmlUtil.serialize (artikler)) derefter: "Node tilføjes korrekt til xml" artikler. '*'. Størrelse () == 5 artikler. Artikel [4] .title == "Kørsel af XML i nøddeskal"}Hvis vi har brug for at ændre strukturen på vores XML med XmlSlurper, vi er nødt til at geninitialisere vores artikler modsætter sig at se resultaterne. Det kan vi opnå ved hjælp af kombinationen af groovy.util.XmlSlurper # parseText og groovy.xmlXmlUtil # serialize metoder.
4.3. Ændring af en node
Som vi nævnte før, GPathResult introducerer en forenklet tilgang til datamanipulation. Når det er sagt, i modsætning til XmlSlurper, vi kan ændre værdierne direkte ved hjælp af nodenavnet eller parameternavnet:
def "Skal ændre node" () {givet: "XML-objekt" def articles = new XmlSlurper (). parse (xmlFile) når: "Ændring af værdi af en af noderne" articles.article.each {it.'release-date '= "2019-05-18"} derefter: "XML opdateres" articles.article.findAll {it.'release-date'! = "2019-05-18"} .isEmpty ()}Lad os bemærke, at når vi kun ændrer værdierne for XML-objektet, behøver vi ikke analysere hele strukturen igen.
4.4. Udskiftning af en node
Lad os nu gå over til at erstatte hele noden. Igen, den GPathResult kommer til undsætning. Vi kan nemt udskifte noden ved hjælp af groovy.util.slurpersupport.NodeChild # erstatteNode, som strækker sig GPathResult og følger den samme konvention om brug af Objekt værdier som argumenter:
def "Skal erstatte node" () {givet: "XML-objekt" def articles = ny XmlSlurper (). parse (xmlFile) når: "Udskiftning af node" articles.article [0] .replaceNode {artikel (id: '5') {title ('Traversing XML in the nutshell') forfatter {fornavn ('Martin') efternavn ('Schmidt')} 'release-date' ('2019-05-18')}} artikler = ny XmlSlurper (). parseText (XmlUtil.serialize (artikler)) derefter: "Node erstattes korrekt" artikler. '*'. Størrelse () == 4 artikler. Artikel [0] .title == "Traversering af XML i nøddeskal"}Som det var tilfældet, når vi tilføjede en node, ændrer vi XML-strukturen, så vi bliver nødt til at analysere den igen.
4.5. Sletning af en node
For at fjerne en node ved hjælp af XmlSlurper, vi kan genbruge groovy.util.slurpersupport.NodeChild # erstatteNode metode simpelthen ved at give en tom Node definition:
def "Skal fjerne artikel fra xml" () {givet: "XML-objekt" def articles = new XmlSlurper (). parse (xmlFile) når: "Fjernelse af alle artikler undtagen dem med id == 3" articles.article .findAll { it.author.'@id '! = "3"} .replaceNode {} artikler = ny XmlSlurper (). parseText (XmlUtil.serialize (artikler)) derefter: "Der er kun én artikel tilbage" articles.children (). størrelse () == 1 artikler. artikel [0] .forfatter. '@ id' == "3"}Igen kræver ændring af XML-strukturen geninitialisering af vores artikler objekt.
5. XmlParser vs. XmlSlurper
Som vi viste i vores eksempler, anvendelsen af XmlParser og XmlSlurper er temmelig ens. Vi kan mere eller mindre opnå de samme resultater med begge. Imidlertid kan nogle forskelle mellem dem vippe skalaerne mod den ene eller den anden.
Først og fremmest,XmlParser analyserer altid hele dokumentet i DOM-ish-strukturen. På grund af det kan vi samtidigt læse fra og skrive ind i det. Vi kan ikke gøre det samme med XmlSlurper da det vurderer stier mere doven. Som resultat, XmlParser kan forbruge mere hukommelse.
På den anden side, XmlSlurper bruger mere enkle definitioner, hvilket gør det nemmere at arbejde med. Vi skal også huske det eventuelle strukturændringer foretaget i XML ved hjælp af XmlSlurper kræver geninitialisering, hvilket kan få et uacceptabelt præstationshit i tilfælde af at foretage mange ændringer efter hinanden.
Beslutningen om, hvilket værktøj der skal bruges, skal tages med omhu og afhænger helt af brugssagen.
6. MarkupBuilder
Bortset fra at læse og manipulere XML-træet, giver Groovy også værktøj til at oprette et XML-dokument fra bunden. Lad os nu oprette et dokument bestående af de to første artikler fra vores første eksempel ved hjælp af groovy.xml.MarkupBuilder:
def "Skal oprette XML korrekt" () {givet: "Nodestrukturer" når: "Brug af MarkupBuilderTest til at oprette xml-struktur" defwriter = ny StringWriter () ny MarkupBuilder (forfatter) .artikler {artikel {titel ('Første trin i Java ') forfatter (id:' 1 ') {fornavn (' Siena ') efternavn (' Kerr ')}' udgivelsesdato '(' 2018-12-01 ')} artikel {titel (' Dockerize din SpringBoot-applikation ') forfatter (id: '2') {fornavn ('Jonas') efternavn ('Lugo')} 'udgivelsesdato' ('2018-12-01')}} derefter: "Xml oprettes korrekt" XmlUtil.serialize ( writer.toString ()) == XmlUtil.serialize (xmlFile.text)}I ovenstående eksempel kan vi se det MarkupBuilder bruger den samme tilgang til Node definitioner, vi brugte med NodeBuilder og GPathResult tidligere.
For at sammenligne output fra MarkupBuilder med den forventede XML-struktur brugte vi groovy.xml.XmlUtil # serialize metode.
7. Konklusion
I denne artikel undersøgte vi flere måder at manipulere XML-strukturer ved hjælp af Groovy.
Vi kiggede på eksempler på parsing, tilføjelse, redigering, udskiftning og sletning af noder ved hjælp af to klasser leveret af Groovy: XmlParser og XmlSlurper. Vi diskuterede også forskelle mellem dem og viste, hvordan vi kunne bygge et XML-træ fra bunden ved hjælp af MarkupBuilder.
Som altid er den komplette kode, der bruges i denne artikel, tilgængelig på GitHub.